Open Source: https://github.com/hanborq/hadoop
Major Features:
1. Worker Pool
Does not spawn new JVM processes for each job/task, but instead start these slot/worker processes at initialization phase and keep them running constantly.
2. Sort Avoidance.
Many aggregation job need not sort.
---------------------
A Hanborq optimized Hadoop Distribution, especially with high performance of MapReduce. It's the core part of HDH (Hanborq Distribution with Hadoop for Big Data Engineering).
Here is our presentation: Hanborq Optimizations on Hadoop MapReduce
HDH (Hanborq Distribution with Hadoop)
Hanborq, a start-up team focuses on Cloud & BigData products and businesses, delivers a series of software products for Big Data Engineering, including a optimized Hadoop Distribution.
HDH delivers a series of improvements on Hadoop Core, and Hadoop-based tools and applications for putting Hadoop to work solving Big Data problems in production. HDH is ideal for enterprises seeking an integrated, fast, simple, and robust Hadoop Distribution. In particular, if you think your MapReduce jobs are slow and low performing, the HDH may be you choice.
Hanborq optimized Hadoop
It is a open source distribution, to make Hadoop Fast, Simple and Robust.
- Fast: High performance, fast MapReduce job execution, low latency.
- Simple: Easy to use and develop BigData applications on Hadoop.
- Robust: Make hadoop more stable.
- Fast: High performance, fast MapReduce job execution, low latency.
- Simple: Easy to use and develop BigData applications on Hadoop.
- Robust: Make hadoop more stable.
MapReduce Benchmarks
The Testbed: 5 node cluster (4 slaves), 8 map slots and 2 reduce slots per node.
1. MapReduce Runtime Environment Improvement
In order to reduce job latency, HDH implements Distributed Worker Pool like Google Tenzing. HDH MapReduce framework does not spawn new JVM processes for each job/task, but instead keep the slot processes running constantly. Additionally, there are many other improvements at this aspect.
bin/hadoop jar hadoop-examples-0.20.2-hdh3u3.jar sleep -m 32 -r 4 -mt 1 -rt 1
bin/hadoop jar hadoop-examples-0.20.2-hdh3u3.jar sleep -m 96 -r 4 -mt 1 -rt 1
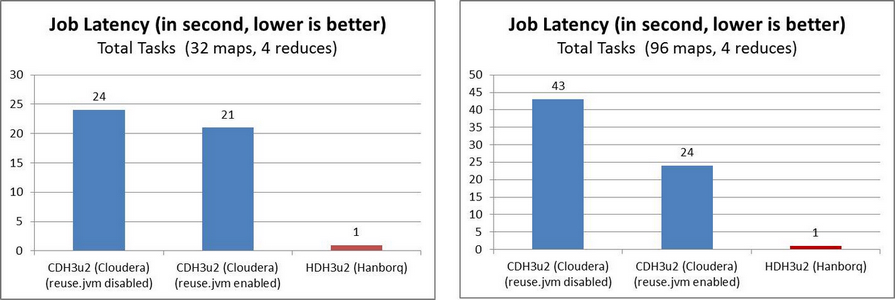
In order to reduce job latency, HDH implements Distributed Worker Pool like Google Tenzing. HDH MapReduce framework does not spawn new JVM processes for each job/task, but instead keep the slot processes running constantly. Additionally, there are many other improvements at this aspect.
bin/hadoop jar hadoop-examples-0.20.2-hdh3u3.jar sleep -m 32 -r 4 -mt 1 -rt 1
bin/hadoop jar hadoop-examples-0.20.2-hdh3u3.jar sleep -m 96 -r 4 -mt 1 -rt 1
2. MapReduce Processing Engine Improvement
Many improvements are applied on Hadoop MapReduce Processing engine, such as shuffle, sort-avoidance, etc.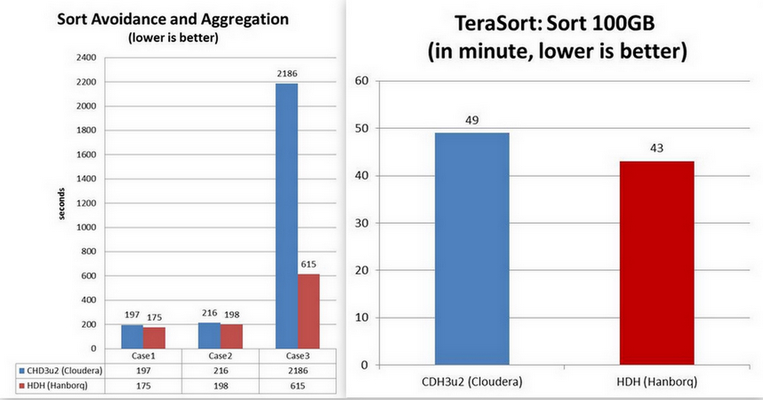
Many improvements are applied on Hadoop MapReduce Processing engine, such as shuffle, sort-avoidance, etc.
Please refer to the page MapReduce Benchmarks for detail.
Features
MapReduce
- Fast job launching: such as the time of job lunching drop from 20 seconds to 1 second.
- Low latency: not only job setup, job cleanup, but also data shuffle, etc.
- High performance shuffle: low overhead of CPU, network, memory, disk, etc.
- Sort avoidance: some case of jobs need not sorting, which result in too many unnecessary system overhead and long latency.
- Low latency: not only job setup, job cleanup, but also data shuffle, etc.
- High performance shuffle: low overhead of CPU, network, memory, disk, etc.
- Sort avoidance: some case of jobs need not sorting, which result in too many unnecessary system overhead and long latency.
... and more and continuous ...
How to build?
$ cd cloudera/maven-packaging
$ mvn -Dnot.cdh.release.build=true -Dmaven.test.skip=true -DskipTests=true clean package
Then use this package: build/hadoop-{main-version}-hdh{hdh-version}, for example: build/hadoop-0.20.2-hdh3u2
Compatibility
The API, configuration, scripts are all back-compatible with Apache Hadoop and Cloudera Hadoop(CDH). The user and developer need not to study new, except new features.
Innovations and Inspirations
The open source community and our real enterprise businesses are the strong source of our continuous innovations. Google, the great father of MapReduce, GFS, etc., always outputs papers and experiences that bring us inspirations, such as:
MapReduce: Simplified Data Processing on Large Clusters
MapReduce: A Flexible Data Processing Tool
Tenzing: A SQL Implementation On The MapReduce Framework
Dremel: Interactive Analysis of Web-Scale Datasets
MapReduce: Simplified Data Processing on Large Clusters
MapReduce: A Flexible Data Processing Tool
Tenzing: A SQL Implementation On The MapReduce Framework
Dremel: Interactive Analysis of Web-Scale Datasets
... and more and more ...
Open Source License
All Hanborq offered code is licensed under the Apache License, Version 2.0. And others follow the original license announcement.



Nice blog i like this post on hadoop. i am looking for such information long time & finally i got it from this post,Thanks for sharing this great information.
ReplyDeleteHadoop Training in Hyderabad
thank you for sharing such a nice and interesting blog with us. hope it might be much useful for us. keep on updating...
ReplyDeleteSEO Company In Chennai
This is extremely helpful info!! Very good work. It is very interesting to learn and easy to understood. Thank you for giving information. Please let us know and more information get post to link.
ReplyDeleteInformatica Training in Chennai
Your blog is very unique and interesting. It makes reader to come back and visit again.
ReplyDeleteSelenium Training in Chennai
i have really enjoyed sharing your website. thank you so much for your sharing this document. this document more useful and improve our knowledge.
ReplyDeletesalesforce training in chennai
Thanks for your wonderful information..
ReplyDeleteSAP SD Training in Chennai
samsung galaxy cases
ReplyDeleteIt's fascinating that a significant number of the bloggers to cleared up a couple of things for me and in addition giving.Most of thoughts can be decent content.The individuals to give them a decent shake to get your point and over the charge.
Accountants Hove
ReplyDeletewhen you post the new artical iam excited to read more artical on this site
I do trust all of the concepts you’ve presented on your post. They’re really convincing and will definitely work. Still, the posts are too brief for newbies. May you please extend them a little from subsequent time?Also, I’ve shared your website in my social networks.
ReplyDeleteMobile App Development Company In Chennai
Android App Development Company In Chennai
Android Application Development Company In Chennai
Custom Web Application Development Company In Chennai
This comment has been removed by the author.
ReplyDeleteThis comment has been removed by the author.
ReplyDeleteYour blog is very nice! Thank you for this wonderful information . i like very much for this article. and it will give the more information from this blog. I also waiting for more than one information this is to get some more processes are available.Thanks for this nice article.
ReplyDeleteWonderful read and would Bookmark it. Thanks
ReplyDeleteDigital marketing courses in Bangalore with placements
This comment has been removed by the author.
ReplyDeletenice blog
ReplyDeleteSelain tiu and akan bisa menghasilkan uang tanpa harsu lagi bekerja dan menghabiskan tenaga anda pastinya. Bergabunglah bersama kami di PokerQiu dan dapatkan juga Bonus Poker dengan modal deposit hanya 10rb rupiah saja saat ini.
ReplyDeleteasikqq
http://dewaqqq.club/
http://sumoqq.today/
interqq
pionpoker
bandar ceme terpercaya
freebet tanpa deposit
paito warna
syair sgp
I’m really impressed with your article, such great & usefull knowledge you mentioned here.
ReplyDelete
ReplyDeleteGood Post! Thank you so much for giving this pretty post, I feel so good to read and useful to improve my knowledge as an updated one, keep it up.
Corporate Training in Chennai
Corporate Training Companies in Chennai
Oracle DBA Training in Chennai
Linux Training in Chennai
Job Openings in Chennai
Oracle Training in Chennai
Tableau Training in Chennai
Unix Training in Chennai
Corporate Training in Adyar
Corporate Training in Annanagar
If your question is who can write an essay for me, you're in the right place. We've got a team of professional writers who are able ace your paper.
ReplyDeleteclash of magic s1 download latest version
ReplyDeleteGood Post! Thank you so much for giving this pretty post
ReplyDeletehttps://bluray4movies.blogspot.com
ReplyDeleteGood Post! Thank you so much for giving this pretty post
ReplyDeleteGood Post! Thank you so much for giving this pretty post
ReplyDeleteWe treat the evaluation process serious and don’t publish fake reviews. In this https://scamfighter.net/review/edubirdie.com review you can learn all information about the company which you won’t find elsewhere.
ReplyDeleteNice blog!! I hope you will share more info like this. I will use this for my studies and research
ReplyDeletetiming spray in pakistan
delay spray pakistan
delay spray in islamabad
timing spray
delay spray in pakistan
Nice Blog
ReplyDeleteYaaron Studios is one of the rapidly growing editing studios in Hyderabad. We are the best Video Editing services in Hyderabad. We provides best graphic works like logo reveals, corporate presentation Etc. And also we gives the best Outdoor/Indoor shoots and Ad Making services.
video editing studios in hyderabad
short film editors in hyderabad
corporate video editing studio in hyderabad
ad making company in hyderabad
I found this is an informative and interesting post so i think so it is very useful and knowledgeable. I would like to thank you for the efforts you have made in writing this article.data sgp
ReplyDeletehttps://www.zotero.org/datasd2019/cv
ReplyDeletehttps://my.desktopnexus.com/datashk/
http://worldcosplay.net/member/839276
https://www.adsoftheworld.com/user/vales1valer
https://slides.com/vales1valer
http://www.cplusplus.com/user/vales1valer/
live sgp
kingdomtoto
ReplyDeletekingdomtoto
kingdomtoto
kingdomtoto
kingdomtoto
kingdomtoto
TOGEL HK
ReplyDeleteTOGEL SYDNEY
Castletoto
KINGHORSETOTO
ReplyDeleteKINGHORSETOTO
KINGHORSETOTO
KINGHORSETOTO
Link Terbaru Dan Terlengkap Kinghorsetoto
KINGDOMTOTO
ReplyDeleteKINGDOMTOTO
KINGDOMTOTO
KINGDOMTOTO
KINGDOMTOTO
KINGDOMTOTO
Prediksi togel online
ReplyDeletePrediksi togel online
Prediksi togel online
Prediksi togel online
Prediksi togel online
Prediksi togel online
Prediksi togel online
Very impressive post,thanks for sharing.Very clear and good content.Keep posting more.
ReplyDeleteData science training institute in btm layout
98toto
ReplyDelete98toto
98toto
98toto
https://98toto2.blogspot.com/
Data sgp
ReplyDeleteData sgp
Data sgp
Data sgp
Data sgp
Bocoran Hk
ReplyDeleteData Hk
Agen Togel Terpercaya
Capsule theory is an excellent concept to talk about, but you can't ignore the relation of capsule theories with Big data platform managed service.
ReplyDeleteWorld Series of Poker yang dimainkan yang dipopulerkan poker turnamen di kasino Amerika. Ini juga merupakan waktu ketika buku-buku poker serius pertama diterbitkan pokerpelangi
ReplyDelete98toto
Back to school Instagram captions
ReplyDeleteBasketball instagram captions
Dance instagram captions
bachelorette party instagram captions
Thank you for taking the time to provide us with your valuable information. We strive to provide our candidates with excellent care
ReplyDeletehttp://chennaitraining.in/final-year-ieee-java-projects-chennai/
http://chennaitraining.in/final-year-ieee-python-projects-chennai/
http://chennaitraining.in/final-year-ieee-vlsi-projects-chennai/
http://chennaitraining.in/final-year-ieee-dot-net-projects-chennai/
http://chennaitraining.in/final-year-ieee-php-projects-chennai/
http://chennaitraining.in/final-year-ieee-big-data-projects-chennai/
https://berbagitipshidupsehat1.blogspot.com/
ReplyDeletehttps://tutorialdietsehat2.blogspot.com/
https://Healthydiet34.blogspot.com/
https://agentogelonlineterpercaya99.blogspot.com/
https://kingdomtoto88.blogspot.com/
https://royaltoto888.blogspot.com/
https://kinghorsetoto88.blogspot.com/
https://royaltoto888.blogspot.com/
https://98toto88.blogspot.com/
Great write-up. I am a big believer in commenting on blogs to inform the blog writers know that they’ve added something worthwhile to the world wide web. what is sushi
ReplyDeleteI enjoyed your blog Thanks for sharing such an informative post. We are also providing the best services click on below links to visit our website.
ReplyDeletedigital marketing company in nagercoil
digital marketing services in nagercoil
digital marketing agency in nagercoil
best marketing services in nagercoil
SEO company in nagercoil
SEO services in nagercoil
social media marketing in nagercoil
social media company in nagercoil
PPC services in nagercoil
digital marketing company in velachery
digital marketing company in velachery
digital marketing services in velachery
digital marketing agency in velachery
SEO company in velachery
SEO services in velachery
social media marketing in velachery
social media company in velachery
PPC services in velachery
online advertisement services in velachery
online advertisement services in nagercoil
Thanks for Sharing - ( Groarz branding solutions )
I enjoyed your blog Thanks for sharing such an informative post. We are also providing the best services click on below links to visit our website.
ReplyDeleteweb design company in nagercoil
web development company in nagercoil
website design company in nagercoil
website development company in nagercoil
web designing company in nagercoil
website designing company in nagercoil
best web design company in nagercoil
web design company in velachery
web development company in velachery
website design company in velachery
website development company in velachery
web designing company in velachery
website designing company in velachery
best web design company in velachery
Thanks for Sharing - ( Groarz branding solutions )
ReplyDeleteRemarkable page! I seriously had our checking. I’m hoping to read simple things a lot more on your side. In my opinion that you have exceptional awareness and even prospect. Now i am quite pleased within this guidance. sushi
Thanks for provide great informatic and looking beautiful blog, really nice required information & the things i never imagined and i would request, wright more blog and blog post like that for us. Thanks you once agian
ReplyDeletebirth certificate in delhi
name add in birth certificate
birth certificate in gurgaon
birth certificate correction
birth certificate in noida
birth certificate online
birth certificate in ghaziabad
birth certificate in india
birth certificate apply online
birth certificate in bengaluru
Nice blog on the web. Today, Emblix solutions as one of the best and top most service-oriented Digital Marketing Agency in Hyderabad and India, Which provides high-quality result-oriented Digital Services ranging from SEO to Web Design, Social Media Marketing and more,
ReplyDeleteThe time when I had s*x at my job. Read the full complete story here.
ReplyDeleteДля женщин из натуральной кожи сумки сумка цена – это эталон крутости и красоты. На их производстве употребляется итальянская кожа и фурнитура, что создает элементам долговечность. Кожа удивляет разнообразием текстур: кроме гладких и матовых представлены велюровые модели, с тиснением под черепаху или перфорированным принтом. Прочная кожа делает изделия надежными. За прикольное оформление ручается команда талантливых дизайнеров, которая следит за новыми трендами.
ReplyDeleteПотрясающе интересныеи еще невероятно правдивые онлайн гадания для предречения вашего будущего - это непременно то, что вы найдете на портале гаданий. Гадание на картах на ближайшее оказывается действенным быстрым и простым способом для получения необходимых сведений из информационного поля Земли.
ReplyDeleteНевероятно креативные и невероятно точнейшие онлайн гадания для уточнении загадывания вашего ближайшего будущего - это то, с чем вы познакомитесь на нашем портале. Гадание на чувства любимого оказывается наиболее приятным и действенным способом для получения необходимых информаций из эфирного поля Земли.
ReplyDeletegreat tips At SynergisticIT we offer the best java bootcamp training in california
ReplyDeleteBitTorrent платформа трудится в бэкграунд режиме и не затрагивает системные запасы ПК. Нецелесообразно транжирить наличные на закупку лицензии с новейшей игрушкой. Всего только пару лет назад новая игра была именно в брендовых магазинах. В нынешнее время каждую игрушку достаточно приобрести в интернете на специализированных платформах. Специфической чертой Уторрент платформ представляется вариант дармовой скачки дистрибутивов каких угодно размеров. Загрузить популярнейшую игрушку можно в рекордно короткий срок - скорость BitTorrent сервера не на шутку велика, например тут игры торрент на русском. Высокие условия игрушки не сумеют напугать современных гиков.
ReplyDeleteЗначительное число развлечений на компьютер выходит ежемесячно. Максимально популярным приемом получить желанную игрушку является скачать игры ужасы на андроид. Ориентироваться в видах кибер игрушек не так просто по причине слишком большого их числа. Устанавливая игрушки с Torrent вы получите невероятный уровень безопасности. Обманщики сумеют использовать непосредственность заказчиков и привязывать трояны. Закачка торрента является обыкновенной процедурой, подходящей к тому же для неопытных посетителей.
ReplyDeleteКомпьютерные игрушки насчитывают больше 30 поджанров. На данном вебсайте кому не лень имеет возможность без каких-либо трудностей https://games9.ru/load/open-world-games/. Грузите подходящую игру по тематике, хотя бы, игрушки про апокалипсис. Тут показаны игры с достоверным международным переводом. Почитатели цикла игр издают персональные сборки. Почти все лицензированные игрушки давненько разрешено скачать на BitTorrent. Не тратьте время попусту - подгружайте в один момент игрушки на передовом сайте Torrent. Фантастический мир на любого клиента и эмоции на сотни часов. Вирусов нет - пользуйтесь надежно uTorrent только на Games9.ru.
ReplyDeleteНа складе лежат также вариации мусорных емкостей из поли материалов. Но при этом, на официальном портале компании СнабТоп.ру клиенты сумеют вдобавок купить на сайте контейнеры для мусора металлические 0.75. Могут быть сформированы доставки баков для сбора ТБО по отдельности.
ReplyDeleteИсключительно надежные кредиторы осуществляют свои действия на платформе Онлайн-займы. Воспользовавшись сервисом быстрый займ онлайн на карту, кто-угодно может самостоятельно подобрать выгодные предложения по займу. Оформите микрозайм на карту на любые цели.
ReplyDeletevery nice Job alert information Free Job Alert
ReplyDeletevery nice Job Alert Website JobAlert247
ReplyDeleteНужно отметить, что проект казино х зеркало сайта работающее предлагает своим посетителям приятные вознаграждения. Дополнительный счет позволит заработать много денег. Верифицируйтесь на портале и смотрите дополнительные средства в своей учетке.
ReplyDeleteТехническая служба круглосуточно придет на помощь и оперативно разрулит наиболее тяжелую проблему. Посмотреть истинность платформы реально на центральной странице casino-x-oficialniy-sayt.com. Учитывайте, что онлайн казино казино х мобильная ни в коем случае не потребует денежных средств за проведение порядка верификации посетителей.
ReplyDeleteВ онлайн-казино FrankCasinoClub вы можете легко обнаружить раздел авторизации на центральной странице портала. Присоединяйтесь к игровой платформе и получайте выгодные бонусы в своей учетной записи. Осуществите разумный выбор – frank casino скачать для android твой шанс на победу! Регистрация на портале азартные игры FrankCasino не занимает много времени.
ReplyDeleteIn recent times, id verification service is greater in preference. One will obtain numerous verification methods on a reliable platform titled Trust Swiftly, and all methods provide much better secureness to any web business. If you have a look at this unique TrustSwiftly website, you will definitely get a lot more information regarding id verification service.
ReplyDeleteStakers ist genau das, wonach Sie gesucht haben, wenn Sie sich für Online Casinos und Wettseiten interessieren. Hier stehen Ihnen immer die aktuelsten Online Casino-Angebote, Bewertungen im Gebiet "Online Casino und Buchmacher" zur Verfügung. Treten Sie uns bei, um ständig auf dem Laufenden zu sein.
ReplyDeleteГадание на рунах на сейчас дает просмотреть, что человека ждет в предстоящем времени. Вариант спрогнозировать грядущие действия непрерывно привлекал людей. Каждый желает узнать собственное грядущее и представляет определенные способы хиромантии наиболее достоверными.
ReplyDeleteКафельная плитка http://www.klincity.com/index.php?subaction=userinfo&user=akilaw используется почти во всех помещениях. На сайте интернет-магазина Легенда Gres любой клиент может выбрать кафель по максимально сходной цене. Широкий ассортимент продукции, реализованный в перечне магазина, доступен всякому по наиболее хорошей цене.
ReplyDeleteБольшой выбор морепродуктов http://www.luisovalles.com/new/index.php?option=com_k2&view=itemlist&task=user&id=47374 и оперативная доставка. Морепродукты лучшего качества представлены в шоу-руме в Москве в любое время. Посетив наш магазин, вы приобретете лишь качественную рыбопродукцию от проверенных дилеров.
ReplyDeleteЗаказать эскортниц реально на сутки или провести командировку в сопровождении удивительной девушки за границу. Лишь сопровождение девушки в значительной степени позволит возвысить социальный статус в различной компании или пред деловыми партнерами. Реальные модели составят для вас пару при походе в ресторан или в период деловой встречи.
ReplyDeleteWas ist das beste Online Casino, mit dem ich mich registrieren kann? Und welche Casinos gibt es überhaupt? Ich fand, dass diese erstaunliche Website wunderino
ReplyDeleteВнесите необходимый элемент для получения уникального вкуса, как пример, рубленый тимьян. Полезно мариновать голень и положить специальных пряностей по душе. Компоненты для готовки курочки демократичны, необходимо только голень и немного специй. Основная тайна спрятана в этапах обжарки. Запечь сочную курицу без специфических премудростей довольно просто https://trebuha.ru/202-grechka-zharenaja-s-indejkoj-i-gribami.html.
ReplyDeleteМясо птицы – особенно востребованный продукт на рынке. Вот, присмотрел свежий рецепт вкуснейших куриных крылышек на сайте http://mail.rent4.today/index.php?subaction=userinfo&user=yraqepaqi. Мягкий вкус и элементарный вариант готовки идеальнейшего кушанья – получить результат можно благодаря пошаговому руководству. Чаще всего на любом столе без проблем встретить зажаренную корочку.
ReplyDeleteСамый практичный пример – на любой кухне обязательно имеется чайник. Аксессуары для кухни возможно символично разбить на две особенные категории – в виде декораций и используемые по назначению, для постоянного использования. На странице маркетплейса «МАКСИДЕН» просто выбрать купить вазу конфетницу по преимущественно выгодной цене.
ReplyDeleteТолько лишь на данном портале Нижний Новгород Уфа жд билеты пользователи имеют возможность заказать билеты удаленно. В настоящее время любой желающий может самостоятельно продумать своё путешествие без непредвиденных переплат. По собственному усмотрению организуйте направление путешествия и время старта Ж/Д состава.
ReplyDeleteНастольные игры и атрибуты для подвижных игр обязательно нужны на природе. Подобрать подходящий инвентарь отдыхая на природе вы можете при помощи огромного каталога вещей для спортивного отдыха площадки МегаМаг. Кстати, вам может потребуется конфетница лебедь купить, это зависит от конкретного места на природе.
ReplyDeleteМеню уважающего себя кафе так или иначе имеет морепродукты. Гурманы со всего мира любят готовить ракообразных на личной кухне. На сайте купить черную икру в нижнем новгороде невероятно легко купить товар, нужно только посетить интерактивный магазин «Красный жемчуг», где находится на самом деле огромный выбор морских деликатесов.
ReplyDeleteВУЗы США не гарантируют стипендиальные места иностранным абитуриентам. Всего лишь благодаря https://liport.ru/obschestvo/440539-obrazovanie-v-ssha-pomosch-v-postuplenii-ot-kompanii-infostudy.html вы сможете получить престижное обучение и стартовать выгодную карьеру. Вам надо примерно $15 000 - $20 000 в год на обучение, число станет изменяться от города, где происходит обучение. Академически подкованные студенты смогут ориентироваться на неполную стипендию. Поступающие из иных стран пройдут подготовку в Соединенных Штатах Америки лишь на платной основе.
ReplyDeleteДля получения помощи по интересующим вопросам, вы сможете обратиться к специалисту компании Info Study или просмотреть материалы на портале https://newspotok.ru/2021/04/23/chastnye-shkoly-v-kanade.html. В период образования ученики могут участвовать в общедоступных акциях, больше всего соответствующих знаниям английского языка. Специализированное образование дает поступление в ВУЗы и неплохое знание английского.
ReplyDeleteДля участия на конкретных соревнованиях вам непременно понадобятся конфетница богемия купить, купить какие реально на маркетплейсе Яндекс. Битки для спорта отлично защитятсохранят твои кисти от травмирования на период спаринга. Спорт – это практичный способ укрепить собственное здоровье.
ReplyDeleteЦена данного материала как правило небольшая фанера.бел. При применении специальной смолы плиты шпона не разбухнут под действием внешних факторов или высокой влажности. По причине перекрестно составленных лент шпона влагопрочный тип фанерной плиты соответствует по прочности натуральной древесине.
ReplyDeleteСкорость работы вентиляторов сушилки является главным коэффициентом для выбора устройства. В большинстве случаев воздух бьет по рукам сразу сверху вниз, но бывают и «погружные» сушки, в виде плоского короба, где необходимо располагать руки сверху вниз. Подбирайте сушилка для рук электрическая купить в новосибирске удобные аппараты на платформе smartdryer.ru для улучшения качества обслуживания посетителей. Чем плотнее воздушный поток, тем живее пользователь решит требуемые дела в туалетной комнате.
ReplyDeleteС развитием web-технологий единовременно оттачивают профессиональные способности киберпреступники, какие работают в Глобальной сети. Интернет сеть дает возможность закачать огромное количество архивов практически даром. Заходя в интернет требуется заблаговременно позаботиться о безопасности стационарного устройства и находящейся на нём информации, дабы посетить https://hydraruzxpnew4af.xn--tr-5ja.com/.
ReplyDeleteВычислить местоположение коннекта в Глобальную паутину по средствам TOR практически нельзя. Благодаря интегрированной протекции юзер станет без заморочек скачивать всю информацию в интернет сети http://travelson.ru/index.php?subaction=userinfo&user=avynykyx. Существует огромное множество анонимных веб-обзорщиков, какие в онлайн режиме прерывают эксперименты атаки на ваш компьютер или умного девайса. Браузер для Глобальной паутины ТОР присоединяется с помощью огромнейшее число прокси-серверов.
ReplyDeleteTOR – самый лучший веб-обозреватель, какой стоит применять для серфинга в сети интернет. Большинство юзеров предполагают, что гарантировать 100% безопасность в Мировой паутине не представляется возможным, но это является большим заблуждением. Нынешнее программное обеспечение АНКОР2 обеспечит своевременную охрану от злодеев http://forum.eduglobe.net/member.php?action=profile&uid=146257.
ReplyDeleteВ отдельных областях ворожба является ложной наукой. Всякие приемы для предсказания будущего употреблялись человеком с давних времен. Хиромантия - наиболее популярные типы предсказания грядущего https://gadanie.fun/gadanie-na-sudbu-onlajn-besplatno/.
ReplyDeleteПорталы копирайтинга – это максимально отличный всякому пользователю способ подзаработать в глобальной сети. На данных платформах пользователи выкладывают детальные задания, выполняя какие пользователь получает вознаграждение на индивидуальный счет учетки. Благодаря фрилансингу возможно реализовывать высокий доход. На портале зеркало гидры онион ссылка всегда представлена работа даже для юных фрилансеров.
ReplyDeleteС целью исполнения денежных заданий требуется работать с недорогими заданиями гидра магазин тор какой-то период. Конечно, выплаты за простые заказы минимальная, но и специализированных навыков аналогичная работа не потребует. Так, клиенту нужно подтолкнуть сообщество или фото в соцсети, именно тогда выбираются исполнители, которые должны логиниться и дописывать хорошие сообщения.
ReplyDeleteВсякая криптомонета работает на специальном криптошифре. Определенную техническую информацию по переводу криптовалюты возможно открыть на страницах портала http://88.lmcpw.net/home.php?mod=space&uid=58224&do=profile. Разновидности криптомонет множатся повсеместно в невероятном количестве. Наиболее востребованными монетами стали BTC и Этериум.
ReplyDeleteПриобретя определенное число криптомонет, спустя некоторый час их реально будет продать еще дороже. http://www.sg0536.com/home.php?mod=space&uid=577149 утверждают, что криптовалюта уже вообще не выйдут из оборота. Увеличить капитал на биткоинах очень легко.
ReplyDeleteОчень часто бывает ситуация, когда человеку требуется несущественное количество денежных средств. Одолжить денежные средства без лишних заморочек довольно просто в микрофинансовой организации микрозайма на qiwi. Встречаются различные случаи, допустим, неожиданная акция в супермаркете на необходимый гаджет, или приглашение на день рождения.
ReplyDeleteОтправляйте денежки в каком угодно направлении без дополнительных процентов, наряду с этим не публикуя собственные данные. Благодаря интернет-магазину зеркало гидра анион рабочее ссылка каждый человек имеет возможность осуществить скрытую сделку. Используйте услуги виртуального сайта Hydra, или сайтом-зеркалом, если центральный сайт недоступен.
ReplyDeleteВ основном, операции при наличии администрации происходят без задержек, покупателю необходимо лишь зайти на пункт выдачи рабочее зеркало гидры санкт петербург и забрать свою покупку. В каждом городе присутствует значительное число адресов выдачи продукта. По результатам удачной оплаты клиенту поступит информация о том, как ему отыскать свою покупку.
ReplyDeleteНаиболее крупных платежные системы требуют полноценной проверки пользователя. Не во всех кошельках нужно прописывать личные данные, необходимо всего лишь найти прибыльную платежную систему. Приобрести иммунитет верификации получится лишь на общественной платформе гидра официальный.
ReplyDeleteЛишь только на регистрация на гидре официальный сайт вы сможете отыскать необходимые вещи. Огромный состав продуктов особенно впечатляет. Виртуальный магазин ГидраРУ – это самый большой развлекательный сайт в рунете. В сети интернет есть громадное множество увеселительных магазинов. Купить нужную вещь по крайне интересной стоимости клиент сумеет только на виртуальной платформе HydraRU.
ReplyDeleteДля оплаты билетов возможно воспользоваться кредиткой, или же виртуальный кошелек Киви. Открыв сайт компании «Автовокзалы Краснодара» и подобрав нужное направление https://anapa-avtovokzal.ru/anapa-evpatoriya/ перейдите в соответствующий раздел оплаты билета. Оплатить билеты через компьютер очень просто, это не тяжелее чем пополнить счет телефона.
ReplyDeleteKINGDOMGROUP SITUS BETTING ONLINE TERBESAR DAN TERPERCAYA
ReplyDeleteʟᴏᴍʙᴀ ʀᴀᴛᴜsᴀɴ ᴊᴜᴛᴀ!!!
LINK DAFTAR DAN PREDIKSI : https://kingdom899.wixsite.com/linkbaru
ᴍɪɴ ʙᴇᴛ : 100 ʀᴜᴘɪᴀʜ
𝚃𝚘𝚝𝚊𝚕 𝟷𝟶𝟸 𝙿𝚊𝚜𝚊𝚛𝚊𝚗
♥️ Pasaran Populer ♥️
💢sɪɴɢᴀᴘᴏʀᴇ
💢ʜᴏɴɢᴋᴏɴɢ
💢sʏᴅɴᴇʏ
💢ʙᴜʟʟsᴇʏᴇ
💢ᴄᴀʀᴏʟɪɴᴀᴅᴀʏ
💢ᴍᴀɢɴᴜᴍ4ᴅ
💢ᴘᴄsᴏ
💢ғʟᴏʀɪᴅᴀ
💢ɴᴇᴡʏᴏʀᴋ
💢ᴏʀᴇɢᴏɴ
💢ᴄᴀʟɪғᴏʀɴɪᴀ
TERSEDIAH 8 GAME TERFAVORIT :
💢 SPADE GAMING ( TERBARU 🔥🔥 ) CASHBACK 10%
- SPADEGAMING SLOT
- SPADEGAMING FISHING HUNTER
- SPADEGAMING VIRTUAL GAMES
💢 SBOBET (NEW GAME)
💢 QUEENMAKER SLOT
💢 SEXY GAMES (BACCARAT DENGAN PENAMPILAN SEXY)
💢 PRAMATIC LIVE
💢 JOKER
💢 IDN PLAY
💢 PRAMATIC SLOT
💢 HABANERO SLOT
💢 TEMBAK IKAN
UNTUK SEMUA GAME SLOT CASH BACK 10% (DARI KEKALAHAN MINIMAL 200RB) DAN UNTUK IDNLIVE CASH BACK 10% ( DARI KEKALAHAN MINIMAL 1JT) DI BAGI SETIAP HARI SENIN
LINK GRUP LOMBA BERHADIAH : https://www.facebook.com/groups/Kingdom.Offficial88
Надежный антивирусный защитник возможно просмотреть на сайте http://kfshequ.cn/home.php?mod=space&uid=6668&do=profile. Программы защиты, загруженные на самом ПК человека, действительно не помешает. Проверенные сборки антивирусных базы в скорые сроки просмотрят домашний ПК и спасут от шпионских кодов.
ReplyDeleteМножество вариантов, какие вы увидите на портале http://bbs.51godream.com/home.php?mod=space&uid=454, абсолютно действительны. Возможно ли спастись от кибернетической атаки, рассмотрим небольшое количество практичных рекомендаций. Воспользуйтесь форумом, где возможно получить актуальные предложения опытных участников сообщества. Существует множество возможностей спасти личный компьютер от хакерских вмешательств.
ReplyDeleteС изменениями ИТ методик в интернет-сети представлено немыслимое число развлекательных сайтов. Выбирайте любимый метод развлечений в интернет-сети на собственный вкус. Всякий клиент может посетить форум или портал развлекательного веб-сайта http://qihou123.com/news/home.php?mod=space&uid=399247.
ReplyDeleteЛюбые пароли от входа хранятся на виртуальных компах в зашифрованном варианте. Пользователям не требуется прописывать личную информацию при верификации аккаунта. Регистрация на площадке гидра нарко проходит совсем просто. Ник юзера – это единственное, что станет доступно сейлеру.
ReplyDeleteАвторизация на проекте http://forum.moto-fan.pl/uzytkownik-atitarin выполняется довольно легко. Людям не потребуется вводить персональную информацию при авторизации аккаунта. Вводимые данные от входа сохранены на виртуальных компах в шифрованном варианте. Логин юзера – это лишь то, что увидит сейлер.
ReplyDeleteКатализатор, установленный на дымоотводящей системе, очень часто разрушается по причине своего износа или механического повреждения. Его разрушение может стать причиной увеличения топливного расхода, снижения общей мощности двигателя и удаление клапана егр, появлению проблем с его запуском.
ReplyDeleteРазличные собственники машин проводят в ручную тюнинг автомобиля, но определенные вещи следует поручить мастерам. Реализуйте незабываемый дизайн в результате окраски дисков покраска дисков под хром. Множество авто дефференцируются не лишь по скорости, но и по дизайну конкретных частей.
ReplyDeleteУ юзеров есть право воспользоваться для оплаты даже лайткоины. Оплаты на Hydra происходят оперативно. Клиенты http://nes-apk.com/index.php?subaction=userinfo&user=ujizafidu требуют использовать только лишь онлайн кошельки, без прописи фамилии.
ReplyDeletehappy-eid-milad-un-nabi-images
ReplyDeleteeid-milad-un-nabi-2021-images
Aaqa-Ka-Milad-Aaya-Lyrics
Eid-Milad-Un-Nabi-Mubarak-Images
Eid-Milad-Un-Nabi-Ki-Haqeeqat-In-Hindi
Eid-Milad-Un-Nabi-In-Quran
undefined
An interesting and noteworthy thing for your site is the special sale of desktop calendars that big sites like Vajegostar.com, Digikala.com, Bargcalendar.com, Chapmatin.com are among the best!
ReplyDeleteРестайлинговые диски http://yspic.net/home.php?mod=space&uid=109538&do=profile не только улучшают вид дисков, но и благотворствуют их защите от разрушительного влияния. Губительное действие агрессивной среды негативно ощущается на общем состоянии колес любой машины. Когда раскрасить диски в гараже, спустя некоторое время напыление начнет рушиться, по новой открывая металлическую поверхность.
ReplyDeleteТуристы имеют возможность запечатлеть понравившуюся композицию. В Калининграде особенно много прекрасных объектов, например, https://gides.ru/guids/. Парки также будут прекрасными местами для посещения. К вашим услугам опытный путеводитель, который расскажет необходимые материалы об объекте архитектуры.
ReplyDeleteДиски конкретного авто – это заметный компонент дизайна, какой очень легко изменить без особых расходов. Покрасить диски на колесах личного автомобиля воспользовавшись такой услугой http://rcmspp.minzdravrso.ru/about/forum/user/192473/ на удивление легко. Диски на колесах авто все время притягивают интерес всех встречных пешеходов и водителей из встречных тачек.
ReplyDeleteИнтерактивные денежные средства начисляются в персональном кабинете юзера. На HydraRU принимают выплаты Юманей и дополнительно переводом мобильного телефона. Пополнение баланса требуемого человека выполняется персонально. Для закупа на гидра hydraruzxpnew4af onion доступны всякие варианты виртуальных денежных средств. Самым оперативным средством проклаты на этот день есть криптовалюты.
ReplyDeleteСовременный потребитель закупает практически все вещи онлайн. Смартфоны и даже программы необходимо заказывать онлайн. Имеется конкретная продукция, купить какую реально только через сеть. На сайте гидра зеркало zerkalo onion 2021 com есть в наличии громадный сортамент продукции на ваш вкус.
ReplyDeleteДля формирования договора пользователю нужно зарегистрироваться на официальном сайте. Залогиниться на портале Гидра просто с помощью какого угодно мобильного устройства, или стационарного компа. Проверить ответственность продавца запросто по оценкам на портале https://hydra.xn--tr-5ja.com. Огромное число ответственных реализаторов отпускают свои продукты по всей территории России.
ReplyDeleteHydraRU дает своим покупателям огромнейший ассортимент предметов по наиболее минимальным ценам от дилеров. Каждый первый посетитель сможет верифицироваться на сайте и анонимно произвести закупку на потребную сумму. На площадке имеется множество изготовителей отличного продукта. Для постоянных пользователей гидра через браузер доступны скидки.
ReplyDeleteВ период декорирования дисков авто не обращают внимания на диаметр колеса. Выкрасить цельнолитые и металлические диски допускается в любом автотранспортном средстве. Окраска дисков в салоне покраска дисков в Москве цены вао позволяет существенно повысить притягательность вашего автомобиля по городу. Индивидуальный образ расписанных колес обозначит тебя на автодороге среди банальной массы типовых тачек.
ReplyDeleteОнлайн площадка гидра шоп позволяет заполучить нужный товар мгновенно. Беспроцентные покупки в сети интернет считаются приоритетом для всякого интернет-магазина. Помимо защиты при покупках покупатели в большинстве случаев желают спрятать персональную информацию.
ReplyDeleteБезопасные сделки в глобальной сети являются первостепенной целью для каждого маркетплейса. Не считая надежности при покупках покупатели в большинстве случаев пытаются спрятать персональную информацию. Виртуальная площадка адрес гидры онион позволит закупить требуемый товар немедленно.
ReplyDeleteТакого рода элементарное приспособление, как чайник, представлен пару видов. Элементарное устройство для кипячения жидкости можно максимально быстро прикупить в маркетплейсе фирмы «МАКСИДЕН» https://www.ozon.ru/seller/dtmarket-200745/kryshki-i-kolpaki-14508/, используя основные параметры фильтрации. Особенно покупают чайник, который нагревает воду на газовой плите.
ReplyDeleteНемыслимое количество надежных продавцов http://learn-bg.com/forum/user/7210-ejeguq обеспечат высококачественный товар по оптимальному курсу. Первоклассный маркет реализует свою работу более шести лет и как и прежде активно развивается. В магазине ГидраРУ присутствует громаднейший выбор продуктов всевозможного предназначения. Доставка продукции из Гидра производится на всей России.
ReplyDeleteВсе материалы юзеров лишь только в закодированном варианте в облачном серваке. Для реализации серьезного уровня кибербезопасности на зеркало гидры онион ссылка нужно выполнить конкретные мероприятия. Благодаря грамотной рекламной компании о Hydra узнают много людей в интернете. IT специалисты онлайн-магазина озаботились о защите реальных юзеров.
ReplyDeleteСделать декорирование колес следует в подготовленных мастерских, где отделку станут выполнять мастера. Когда вы запланировали выделиться и украсить свой автомобиль – самое время подкрасить диски в профилированной мастерской порошковая покраска дисков рязань. Для каждого сплава металла присутствуют необходимые составы, которые способны не облупливаться на дисках ну очень долгое время. Покрытие на диске замедлит разрушение металла.
ReplyDeleteРемонт наш заканчивается, это вместе с тем и радостно (так как приходит мой любимый этап украшения и "обуючивания"), и грустно, что кажеться всё сделано. сайт
ReplyDeleteЗаходите в сеть маркета http://xn----7sbaa0corncdgm.xn--p1ai/index.php?subaction=userinfo&user=yzaxuvi только в режиме инкогнито. Надежная шифровка обеспечит отличную величину безопасности для новых покупателей маркетплейса Гидра. Вначале стоит использовать для регистрации на сайте Hydra суперсовременный протокол TOP. Вследствие многократной переадресации никто в мире не может отыскать юзера.
ReplyDeleteОнлайн-магазин Hydra обеспечивает своим клиентам высокий уровень защиты при проведении всякой операции. С помощью портала гидра зеркало на сегодня посетители обретут доступный показатель безопасности. Достаточно пройти верификацию на сайте ГидраРУ, и пользовательская информация направится для хранения в зашифрованном виде на виртуальном компьютере.
ReplyDeleteЦелый ряд ответственных поставщиков продают свои посылки в любом направлении РФ. Залогиниться на портале Гидры возможно с помощью какого угодно мобильного устройства, или домашнего компьютера. Для осуществления контракта вам нужно логиниться на главной площадке. Проверить добросовестность магазина можно по характеристикам на странице http://iawbs.com/home.php?mod=space&uid=521225.
ReplyDeleteПользователи применяют для добычи https://s-usd.com/ видеокарты новейшего поколения или специальные антимайнеры. Производительное оборудование для добывания криптовалюты стоит максимально дорого, но самоокупаемость максимальная. Для майнинга монет требуется весьма мощное вычислительное оборудование.
ReplyDeleteЕсли покрасить диски самолично, спустя время краска начнет разрушаться, по новой оголяя слой металла. Покрашенные диски покраска дисков в солнечногорске не только совершенствуют отображение дисков, но и помогают их защите от критического влияния. Разрушительный эффект наружной атмосферы отрицательно отражается на техническом состоянии колес какой угодно автомашины.
ReplyDeleteПосле оплаты пользователю направят информацию о районе, где возможно взять оплаченный товар. В первую очередь прийдется отобрать нужный продукт в одном из магазинов Hidra. По адресу hydra2web зеркало показан список максимально популярных торговцев маркета.
ReplyDeleteДля конкретного вида металла доступны особые покрытия, способные держаться на колесах максимально длительный период. Сделать окрашивание дисков стоит в специализированных автомастерских, где отделку делать специалисты. Если только вы думаете отличиться и украсить личный автотранспорт – пришло время подкрасить колеса в специализированном салоне https://disk-technology.ru/. Краска на дисках предотвращает коррозию металла.
ReplyDeleteПубликуется громаднейшее количество линков, через которые покупатель сумеет войти на hydra2web ссылка. Действительный каталог дополнительных адресов имеется возможность легко открыть в мировой паутине. Для начинающих клиентов может быть трудно войти на торговый маркетплейс ГидраUnion. Как залогиниться на портал ГидраРУ с персонального компьютера?
ReplyDeleteНемыслимый список вещей hydraclubbioknikokex7njhwuahc2l67lfiz7z36md2jvopda7nchid буквально поражает воображение. Для идентификации на портале Гидра допускается использовать вспомогательную ссылку главной страницы Хидра. Покупателям портала доступны сотни дилеров с какими угодно вещами. Делайте только лишь безопасные варианты оплаты веществ. Адреса для вхождения на сайт Gidra без конца добавляются.
ReplyDeleteЧистку в помещении поможет сделать классическая швабра с тряпочкой из синтетического материала https://www.ozon.ru/seller/dtmarket-200745/shchiptsy-kuhonnye-1710/. Незначительные мелочи, как подстаканники или салатница только украсят каждодневный завтрак. Без кастрюль нереально осуществить приготовление пищи. Для нормального уклада непременно стоит приобрести кастрюли.
ReplyDeleteМашинные диски всегда притягивают интерес всех встречных пешеходов и собственников из мимо проезжающих авто. Покрасить диски на колесах вашего автотранспортного средства воспользоваться этой услугой http://www.vidown.cn/bbs/home.php?mod=space&uid=389282 особенно просто. Колеса конкретной автомашины – это тот предмет дизайна, какой очень легко изменить без крупных капиталовложений.
ReplyDeleteОсобой уникальности вашему автомобилю придадут светоотражающиеся колеса или специальное покрытие хромирования. Агрессивная дорожная среда, вода и щебень, каждую минуту рушат цельнолитые диски, так что им необходима дополнительная защита. Окрашивание дисков http://www.molifan.net/space-uid-1417059.html содержит не только лишь стайлинговое, но и практическое содержание. Колеса автомобиля каждую минуту взаимодействуют с мусором на дорожном покрытии.
ReplyDeleteНа странице HydraЮнион очень трудно приобрести вещи нормальным способом, а перевод принимают только на криптовалютные кошельки. Вот здесь https://www.pcweek.ua/forum/view_profile.php?UID=63433 выставлен весь перечень выставленного товара. На HydraЮнион представлено очень в избытке фирменного товара, который доступен всем покупателям интернете.
ReplyDeleteУсердно выбирайте продукт, сопоставив стоимость в лучших маркетплейсах платформы ГидраUnion. В обязательном порядке просмотрите рейтинг реализаторов, свежий список представлен по адресу http://www.hotspotnews.ca/home.php?mod=space&uid=6032. Для обслуживания покупателей работает постоянно действующая поддержка. Сотрудники администрации маркетплейса круглосуточно наблюдают за соблюдением сделок реализации в магазине.
ReplyDeleteНа портале http://bbs.idhcn.com/home.php?mod=space&uid=139297 есть более чем тридцати пар валют в цифровом виде. Более выгодные предложения в настоящее время – это пересчет криптовалюты на Киви. С помощью платформы отслеживания валютных пунктов KursоФ вы имеете возможность просчитать наиболее благоприятный тариф.
ReplyDeleteИзменение криптографии дало средство всем покупателям ресурса http://www.koelschejunge.koeln/profile.php?lookup=432 устраивать персональные сделки на любом расстоянии. Клиенту нет необходимости самостоятельно видеться с коммерсантом, какую угодно покупку доступно провести онлайн. С целью проплаты вещей на форуме Гидра берут цифровые платежные системы, либо эфириум.
ReplyDeleteРазвитие крипты дает способ любым посетителям магазина http://www.tomomoto.co.jp/bbs/home.php?mod=space&uid=103790&do=profile проводить индивидуальные покупки по всей стране. С целью покупки веществ в онлайн-магазине HydraЮнион берут интерактивные платежные системы, либо эфириум. Тебе нет нужды персонально встречаться с продавцом, всякую покупку доступно оплачивать онлайн.
ReplyDeleteBij Online Casino 2Go vind een top 10 lijst van de beste online casinos van Nederland in één overzicht.
ReplyDeleteDownload Latest Hindi pdf Book Visit Website Education Get Job
ReplyDeleteDownload Letest Turkey Mod APK visit IndirAPK
На главной странице компании «РЭП» в городе Барнаул выставлен большой реестр порообразователей. Подобрать требуемое оборудование http://yijiatang.com/home.php?mod=space&uid=91505 покупатели смогут в прейсткуранте готовой продукции. Технологические устройства для создания пара, по большей части, работают на каменном угле, но имеются котлы и на мазуте.
ReplyDeleteМгновенный подогрев воды и получение пара зависит от многих параметров. Для проектирования котельного аппарата по персональным требованиям, организации следует указать детальные параметры. Как пример можно применять http://520life.cn/home.php?mod=space&uid=93339 аналогичное оборудование из списка расположенных на портале генераторов пара.
ReplyDeleteКомпания Gides осуществляет свою работу в среде организации туристического бизнеса довольно давно. Путешествия по родным городкам – в настоящее время популярное и хорошее увлечение для всех желающих. На экскурсии запросто изучить прошлое объектов архитектуры, послушать историю гида и сделать фото для памяти. Только лишь https://krasnodar-avtovokzal.ru/yalta-krasnodar/ даст возможность туристам по-настоящему насладиться экскурсиями в городке.
ReplyDelete블랙잭 - 기본 전략 및 팁 - 슈터카지노
ReplyDeleteБольшой игровой проект по проведению досуга в сети интернет – hydra торговая
ReplyDeleteНа проекте Gidra нет возможности закупить покупку классическим способом, а перевод принимают именно через электронный кошелек. На Hidra представлено более чем много специфического товара, доступного всем посетителям интернет-сети. Вот тут как пополнить баланс гидры в первый раз представлен настоящий список продаваемого товара.
ReplyDeleteНужно лишь залогиниться на портале HydraRU, а ваши данные направится для хранения в зашифрованном формате на виртуальном серваке. Проект Hydra предоставляет всякому пользователю высочайшую степень скрытности при выполнении всякой транзакции. С помощью сервиса зеркало гидры онион тор посетители получат доступную степень безопасности.
ReplyDeleteСпециальное оборудование не нужны, для оформления виртуального номера достаточно только ПК. Tel Com гарантирует для вас стационарную связь для реализации разговоров в любом городе. Комплекс услуг номер телефона способствует фиксированию звонков или поставить человека на ожидание. При пользовании виртуального телефона ставится специализированный софт.
ReplyDeleteКаким образом заглянуть на популярную платформу гидра вход ссылка на компьютере
ReplyDeleteКомпания TELCOM оформляет своим клиентам возможность введения IP номера. На территории Нижнего Новгорода включение виртуального номера от компании TELCOM – это особенно приемлемое предложение на рынке. Именно красивый номер позволяет настроить отличное качество телефонии и доступ на телефон на протяжении всего рабочего дня.
ReplyDeleteБольшое число обязательных продавцов гидра даркнет представят путевый продукт по низкой цене. Инновационный интернет-магазин реализует частную практику шести лет и продолжает энергично совершенствоваться. Поставка продукции из Гидра реализовывается на всей РФ. На форуме ГидраРУ представлено огромнейший сортамент продуктов всякого назначения.
ReplyDeleteАнонимный заход на маркетплейс Hydra RU
ReplyDeleteНа Hydra получают проплаты PayPal и даже пополнением на мобильный телефон. Для оплаты на гидра сайт hydparu zerkalo site доступны любые варианты интерактивных денежных средств. Повышение баланса каждого человека выполняется самостоятельно. Самым-самым актуальным типом проплат на сей час есть эфириум. Онлайн средства зачисляются в основном кабинете клиента.
ReplyDeleteТокены – это независимая платежная система, обеспечивающая 100% анонимность покупателю. Наличествует немало групп криптовалют для покупки вещей в интернет-сети. Как правило на зайти на гидру через браузер переводят итериум или биткоин. В данное время наиболее быстрый шанс отовариться инкогнито в интернет-сети – это прибегнуть к биткойну.
ReplyDeleteНа платформе Гидра присутствует немыслимый ассортимент товаров любого предназначения. Доставка продуктов из Гидры выполняется по территории РФ. Проверенный маркетплейс проводит характерную практику с 2015 года и как и прежде активно совершенствуется. Огромное число надежных собственников hydra com зеркало обеспечат высококачественный продукт по выгодному тарифу.
ReplyDeleteВыполнив перевод клиенту представят данные о районе, где нужно взять оплаченный пакет. Для начала необходимо отобрать необходимый продукт в любом из маркетов Hydra RU. По адресу гидра обход показан перечень максимально популярных продавцов маркетплейса.
ReplyDeleteБезымянный вход на сайт гидра купить наркотики – необходимые гаджеты по действительно оптимальной стоимости
ReplyDeleteСамый элементарный путь взлома – это установка вредоносных программ, для примера, клавиатурные шпионы. Мошенники могут войти на девайс пользователя и заполучить интернет-доступ к имеющейся инфе. Основным куском интернет безопасности является сохранность сетевого устройства, через которое устанавливается выход в интернет http://television.im/profile.php?u=edobysu.
ReplyDeleteДоля программ или услуг на платной основе, тем не менее, множество проведения досуга находятся в виде ознакомительных данных. Платформа «Гидра» дозволяет соратникам сети подыскивать товарищей за счет обсуждения на заданную их тему. На платформе http://scat-vipfile.com/index.php?subaction=userinfo&user=atiquji ещё есть большое число занятной информации – свежайшие образовательные курсы, программы и магазин товаров.
ReplyDeleteМожно ли надежно совершить скрытую в глобальной паутине https://hpc.man.poznan.pl/userinfo.php?uid=7634
ReplyDeleteПервой целью злоумышленников оказывается интернет-атака персонального ПК. В период атаки кибер-преступников клиент вообще не поймет, что на личном компе находится чужой софт. Обеспечить доступ к дебетовым счетам клиента для матерого хакера не так уж и сложно. Применяйте http://bbs.softba.cn/home.php?mod=space&uid=57668 для доступа на информационный проект Hydra.
ReplyDeleteНа HydraRU взимают оплату Юманей и даже переводом смартфона. Пополнение баланса каждого юзера проходит персонально. Для закупа на https://kivy.club/home.php?mod=space&uid=11688 используются всякие типы виртуальных денег. Интерактивные средства зачислят на аккаунт клиента. Наиболее актуальным средством проплат в настоящее время считается криптовалюта.
ReplyDeleteПриродные происшествия или обрядовые приношения животных в дар основали определенное объяснение обнаруженного. Ведущие методы ворожбы родились тысячелетия тому назад до нашей эры. Правдивое гадание Таро является наиболее вероятным способом предсказать грядущее личности.
ReplyDeleteНа форуме hydra телеграмм кроме того найдется громадное число увлекательных материалов – тематические учебные курсы, игрушки и маркетплейс с товарами. Немного дистрибутивов или сервисов за донат, тем не менее, львиное количество проведения досуга имеются в виде демо данных. Платформа «Гидра» способствует пользователям сети подбирать соратников в результате обсуждений на привлекшую их тему.
ReplyDeleteСовременный потребитель берет абсолютно значительное число товаров через интернет. Мобильные телефоны и даже программное обеспечение благоразумно покупать онлайн. Есть особенная продукция, закупить которую реально лишь только онлайн. На сайте гидра сайт наркотиков выставлен громаднейший выбор товаров на любой кошелек.
ReplyDeleteТОР – лучший браузер, какой рекомендуется применять для серфинга в интернет сети. Новейшее ПО http://www.victorcastro3d.com/2012/11/basement.html обеспечит качественную охрану от преступников. Многие пользователи думают, что гарантировать сто процентную защиту в инете нереально, но это является существенным предрассудком.
ReplyDeleteСайт «Гидра» позволяет соратникам сети подыскивать коллег за счет обсуждений на интересующую их тему. На форуме http://www.199997.com/bbs/home.php?mod=space&uid=175304&do=profile еще и найдется громаднейшее множество занимательных материалов – специальные видео курсы, игрушки и магазин с товарами. Немного архивов или услуг за деньги, тем не менее, множество развлечений представлены в качестве демонстрационных материалов.
ReplyDeleteПредупреждение внедрений кибер-мошенников – надежные консультации на познавательном сайте Hydra http://lalcfashion.com/member/index.php?uid=eneret
ReplyDeleteДля закупки на http://jesusrock.net/profile/3784-umelitefi используются любые виды электронных денежных средств. На ГидраРУ осуществляют операции WebMoney и дополнительно пополнением на смартфон. Повышение баланса конкретного юзера происходит единолично. Онлайн денежные средства зачислят в личном кабинете покупателя. Наиболее значительным видом проклаты сегодня является криптовалюта.
ReplyDeleteПри оплате товаров http://internat-nov.ru/index.php/forum/user/25147-eqitoq, в общем случае, используются электронные платежи. Приобрести необходимый товар на HydraRU можно за счет электронных денег или эфириума. Средства при сделке идут на временный счет маркета, а после приемки вещей – вернутся собственнику. Абсолютно все юзеры получают Hydra RU объективную защиту от владельцев платформы.
ReplyDeleteВойти на страницу Гидры реально при помощи любого телефона, либо ПК. Для выполнения закупки клиенту достаточно залогиниться на официальной площадке. Целый ряд опытных продавцов направляют свои посылки по всей территории страны. Проверить добросовестность торговца запросто по мнениям на сайте http://2626.site/home.php?mod=space&uid=251097.
ReplyDeleteВ наши дни 90 процентов всех торговых операций проходят в интернет-сети. Магазин реализует продукцию на протяжении шести лет, и за столь многолетний промежуток времени сумел зарекомендовать себя как лучшая торговая площадка. Hydra – это инновационный магазин, на каком есть возможность закупить необходимые изделия по действительно выгодной цене. На сайте http://fr79056g.bget.ru/index.php?name=account&op=info&uname=eginuk вы можете приобрести вещи на индивидуальный вкус и стоимость.
ReplyDeleteВозможно применить запасную ссылку для совершения покупок на маркете Гидра. Для входа на http://vegetarian-kuhnya.com/forums/users/emimeraw/ нужно установить новый веб-браузер – TOP. Админы проекта Гидра непрерывно обновляют актуальные адреса для авторизации на форум. Только за счет браузера ТОР какой угодно клиент может войти в темный интернет.
ReplyDeleteВ случае возникновения спора вы сможете написать к руководству платформы Hydra в интересах решения любых задач, в этом случае покупателю всенепременно окажут поддержку. Процесс продаж в интернет-магазине http://www.data-basis.ru/forums/user/13569-osicop строится на положительной оценке зарегистрированных юзеров. При совершении хорошей операции пользователь «рисует» продавцу отличную оценку, что для сторонних юзеров будет значить подтверждением для осуществления новых сделок.
ReplyDeleteВ целях оплаты вещей в онлайн-магазине UnionГИДРА привлекают электронные платежные системы, а также криптографию. Посетителю нет необходимости персонально видеться с коммерсантом, всякую закупку доступно оформить дистанционно. Становление крипты дало перспективу всем посетителям проекта http://mcrb.minzdravrso.ru/about/forum/user/217554/ устраивать индивидуальные сделки по всей стране.
ReplyDeleteКонечно взгляните оценку продавца, новый каталог размещен по url http://www.kbeautybee.com/2017/09/seam-power-ampoule-hydra.html. Хозяева портала всегда следят за соблюдением договоров торговли в магазине. Для спокойствия клиентов предусмотрена постоянная поддержка. Основательно подбирайте товар, сопоставляя стоимость в различных онлайн-магазинах сайта ГидраUnion.
ReplyDeleteЭлектронные кошельки, по большей части, являются анонимным способом оплаты вещи в интернете. При регистрации цифрового кошелька элементарно верифицировать базовый статус без оформления паспорта. Не помешает понимать, что во время перемещения денег с электронного кошелька, владелец онлайн-магазина http://crazy.pokuyo.com/home.php?mod=space&uid=46719 не сумеет записать частные данные посетителя.
ReplyDeleteПроект http://mama7d.ru/forums/user/ikymiku/ предлагает собственным пользователям немыслимо широкий запас нужных продуктов по наиболее низким ценам. Когда вы предполагаете, что брать требуемые товары по выгодной стоимости осуществимо лишь только на страницах топовых онлайн-магазинов, то глубоко неправы. Покупайте продукты лишь у авторитетных продавцов в магазине Hydra.
ReplyDeleteПосле оплаты юзеру предоставят данные о месте, где требуется взять оформленный продукт. В первую очередь надо выбрать подходящий продукт в любом из маркетплейсов Hidra. По адресу http://zhurnal-sait.ru/index.php?subaction=userinfo&user=ypavux выставлен перечень максимально актуальных поставщиков форума.
ReplyDeleteБлагодаря бесконечной переадресации вообще никто не имеет возможности найти покупателя. Многоканальное шифрование создает отличную степень безопасности для всех посетителей проекта Гидра. Входите в систему маркетплейса гидра hydra Иркутск только в режиме невидимка. Сперва нужно применить для авторизации на форуме Hydra RU суперсовременный протокол TOP.
ReplyDeleteНезависимости в интернете давненько нет в той интерпритации, как ранее, возьмем к примеру, 20 лет назад. Махинаторы имеют способ оформить противозаконные операции с денежками юзеров. Авторизация пользователей http://cqinca.com/home.php?mod=space&uid=102680&do=profile в интернете потребуется с целью предотвращения органами правопорядка противоправных махинаций.
ReplyDeleteКибербезопасность относительно недавно считается специализированным видом для гарантии удобной функциональности в сети. К примеру, зайти на гидру через браузер располагает конкретными советами, с целью не стать пострадавшим от злоумышленников в Мировой паутине. Именно высокий показатель осведомленности обеспечит пользователям протекцию частных данных.
ReplyDeleteАдмины наблюдают, чтобы все размещенные дилеры детально выполнили контракты. Клиент получит уверенную гарантию при получении товаров в торговая площадка гидра. Магазин Hydra является посредником всех торговых процессах между клиентом и продавцом. Большой ассортимент вещей маркетплейса каждый день пополняется актуальными вещами по самой прибыльной цене.
ReplyDeleteИнтерактивные игрушки и личностные взаимосвязи между юзеров способствует создавать объединения товарищей по определенным сферам. И http://1.cronusmax.cn/home.php?mod=space&uid=13674 – первый из преимущественно открываемых порталов, предоставляющий постоянным юзерам огромный решение для проведения досуга. В интернет-сети размещено огромное количество мест проведения досуга.
ReplyDeleteНеобходимо учесть, что при транзакции средств с виртуального кошелька, собственник магазина http://msk-ru.ru/index.php?subaction=userinfo&user=avenupab не сможет переписать личные данные юзера. Во время оформлении цифрового кошелька можно взять базовый статус без предоставления документов. Электронные кошельки, большей частью, станут не отслеживаемым вариантом проплаты вещи в интернет-сети.
ReplyDeleteОнлайн деньги начисляют в личном кабинете пользователя. Залив баланса всякого юзера выполняется единолично. Для закупки на гидра интернет магазин применяют различные виды электронных средств. На Hydra RU получают выплаты Юмани и дополнительно переводом на мобильный телефон. Наиболее важным средством проплат на сей час является криптовалюта.
ReplyDeleteВон здесь http://www.sjzshequ.net/home.php?mod=space&uid=115912 имеется действенный каталог выставленного товара. На платформе Hydra тяжело получить покупку стандартным приемом, а оплата принимается только лишь через виртуальные счета. На Gidra найдется более чем в избытке определенного товара, который доступен всем покупателям интернет-сети.
ReplyDeleteДля первого раза необходимо выбрать подходящий продукт в любом из маркетплейсов Gidra. По ссылке http://www.biz-plan.ru/forum/view_profile.php?UID=182397 представлен рейтинг наиболее известных поставщиков портала. Выполнив перевод покупателю направят информацию о районе, где можно забрать купленный продукт.
ReplyDeleteОформив электронный кошелек реально верифицировать минимальный статус без передачи паспорта. Виртуальные кошельки, большей частью, станут серым способом покупки вещей в сети. Необходимо понимать, что во время перевода денег с электронного кошелька, хозяин маркетплейса http://www.dreamteammoney.com/index.php?showuser=783780 не сумеет просмотреть персональные данные клиента.
ReplyDeleteБольшинство клиентов магазинов требуют закупляться полностью безопасно. В сети в высшей степени огромное количество современных магазинчиков. Выискивая в сети интернет особые вещи, пользователь в итоге сталкивается с сайтом Hydra. Наиболее добротный айти рынок в интернет-сети находится на портале http://fddxta.vidown.cn/bbs/home.php?mod=space&uid=423666.
ReplyDeleteСуществует востребованная продукция, приобрести которую возможно всего лишь по интернету. В магазине http://ahuazykj.com/shlf/home.php?mod=space&uid=792 есть громадный выбор продуктов на любой кошелек. Продвинутые люди скупают практически огромную часть товаров по интернету. Мобильные телефоны и даже ПО удобно заказывать в онлайне.
ReplyDeleteСтоит учитывать, что приоритетное количество клиентов разыскивают всякие интерактивные серверы. На сайтах http://forum.cima.ru/member.php?u=14960 юзеры отыщут громадной число забав, в том числе самый большой портал для общения между единомышленниками вирт сообщества. Больше всего клиенты в мировой сети играют в виртуальные проекты.
ReplyDeleteПортал Hydra предоставляет возможность пользователям сети подыскивать коллег по причине обсуждения на конкретную их тематику. Доля игр или сервисов платные, но существенное число развлечений находятся в качестве ознакомительных источников. На форуме http://120.79.50.14/home.php?mod=space&uid=115753&do=profile еще и находится громадное множество полезной информации – свежайшие образовательные курсы, дистрибутивы и маркетплейс с товарами.
ReplyDeleteВажно учесть, что при переводе денег с цифрового кошелька, продавец магазина http://sv-sulgen.de/index.php?option=com_easybookreloaded не будет записать персональную информацию покупателя. Виртуальные кошельки, чаще всего, будут серым способом покупки вещи в сети. После оформлении виртуального кошелька можно верифицировать анонимный статус без предоставления паспорта.
ReplyDeleteЗнаменитый онлайн-магазин http://wotspeak.org/index.php?subaction=userinfo&user=ijijyty располагается в темной сфере глобальной паутины. Hidra числится максимально большим сайтом, реализующий товары особого назначения. Сотни реализаторов и приемлемые ценники – это основные позитивные обстоятельства, почему пользователи скупляются на Гидра.
ReplyDeleteОгромнейшее число схем защиты, что пользователи прочитают на сайте gidra zerkala8 site Краснодар, максимально действительны. Можно ли обезопаситься от кибер атак, рассмотрим небольшое количество грамотных советов. Воспользуйтесь форумом, на котором реально получить практические советы опытных участников сообщества. Есть огромнейшее множество способов защитить собственный ПК от сетевых атак.
ReplyDeleteСтоит только зарегистрироваться на платформе HydraRU, и личные сведения направится для хранения в зашифрованном формате на удаленном компьютере. За счет проекта гидра интернет магазин клиенты получат максимальную степень скрытности. Онлайн-магазин ГидраРУ предоставляет каждому пользователю высочайший уровень скрытности при выполнении определенного контракта.
ReplyDeleteЗа счет бесчисленной переадресовки ни один человек не сможет проверить пользователя. Обширная шифровка создает солидный уровень безопасности для всех юзеров проекта Hydra. Заходите в сеть маркета гидра топ только лишь в режиме инкогнито. Правильнее использовать для авторизации на портале Гидра новейший протокол TOP.
ReplyDeleteПроверенный антивирусный защитник можно загрузить на портале гидра официальный магазин. Защита от вирусов, загруженная на рабочем ПК пользователя, также не помешает. Проверенные пакеты базы антивируса мгновенно отсканируют персональный ПК и удалят все шпионские коды.
ReplyDelete