Major Features:
1. Worker Pool
Does not spawn new JVM processes for each job/task, but instead start these slot/worker processes at initialization phase and keep them running constantly.
2. Sort Avoidance.
Many aggregation job need not sort.
---------------------
A Hanborq optimized Hadoop Distribution, especially with high performance of MapReduce. It's the core part of HDH (Hanborq Distribution with Hadoop for Big Data Engineering).
HDH (Hanborq Distribution with Hadoop)
Hanborq, a start-up team focuses on Cloud & BigData products and businesses, delivers a series of software products for Big Data Engineering, including a optimized Hadoop Distribution.
HDH delivers a series of improvements on Hadoop Core, and Hadoop-based tools and applications for putting Hadoop to work solving Big Data problems in production. HDH is ideal for enterprises seeking an integrated, fast, simple, and robust Hadoop Distribution. In particular, if you think your MapReduce jobs are slow and low performing, the HDH may be you choice.
Hanborq optimized Hadoop
It is a open source distribution, to make Hadoop Fast, Simple and Robust.
- Fast: High performance, fast MapReduce job execution, low latency.
- Simple: Easy to use and develop BigData applications on Hadoop.
- Robust: Make hadoop more stable.
MapReduce Benchmarks
The Testbed: 5 node cluster (4 slaves), 8 map slots and 2 reduce slots per node.
1. MapReduce Runtime Environment Improvement
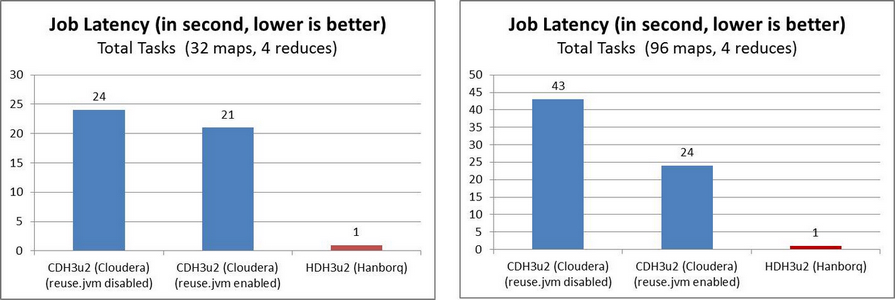
In order to reduce job latency, HDH implements
Distributed Worker Pool like Google Tenzing. HDH MapReduce framework does not spawn new JVM processes for each job/task, but instead keep the slot processes running constantly. Additionally, there are many other improvements at this aspect.
bin/hadoop jar hadoop-examples-0.20.2-hdh3u3.jar sleep -m 32 -r 4 -mt 1 -rt 1
bin/hadoop jar hadoop-examples-0.20.2-hdh3u3.jar sleep -m 96 -r 4 -mt 1 -rt 1
2. MapReduce Processing Engine Improvement
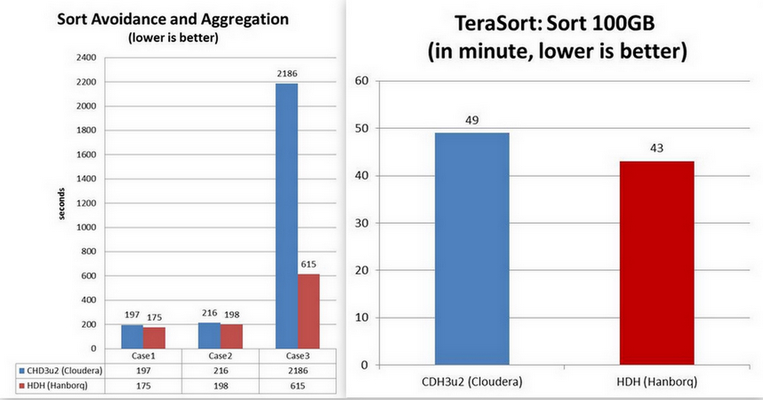
Many improvements are applied on Hadoop MapReduce Processing engine, such as shuffle, sort-avoidance, etc.
Features
MapReduce
- Fast job launching: such as the time of job lunching drop from 20 seconds to 1 second.
- Low latency: not only job setup, job cleanup, but also data shuffle, etc.
- High performance shuffle: low overhead of CPU, network, memory, disk, etc.
- Sort avoidance: some case of jobs need not sorting, which result in too many unnecessary system overhead and long latency.
... and more and continuous ...
How to build?
$ cd cloudera/maven-packaging
$ mvn -Dnot.cdh.release.build=true -Dmaven.test.skip=true -DskipTests=true clean package
Then use this package: build/hadoop-{main-version}-hdh{hdh-version}, for example: build/hadoop-0.20.2-hdh3u2
Compatibility
The API, configuration, scripts are all back-compatible with
Apache Hadoop and
Cloudera Hadoop(CDH). The user and developer need not to study new, except new features.
Innovations and Inspirations
... and more and more ...
Open Source License




